How research actually happens.
A five-stage pipeline across seven frontier models, a 180-source universe screened down to ~40 cited per report, and fourteen gates that block a memo from shipping. The reasoning trace and citations ship with the verdict.
Five stages. The first one is with you. The next four run automatically.
Intake & framing
Your one-sentence pitch becomes a structured brief of twelve questions, each mapped to a downstream decision and a named kill criterion.
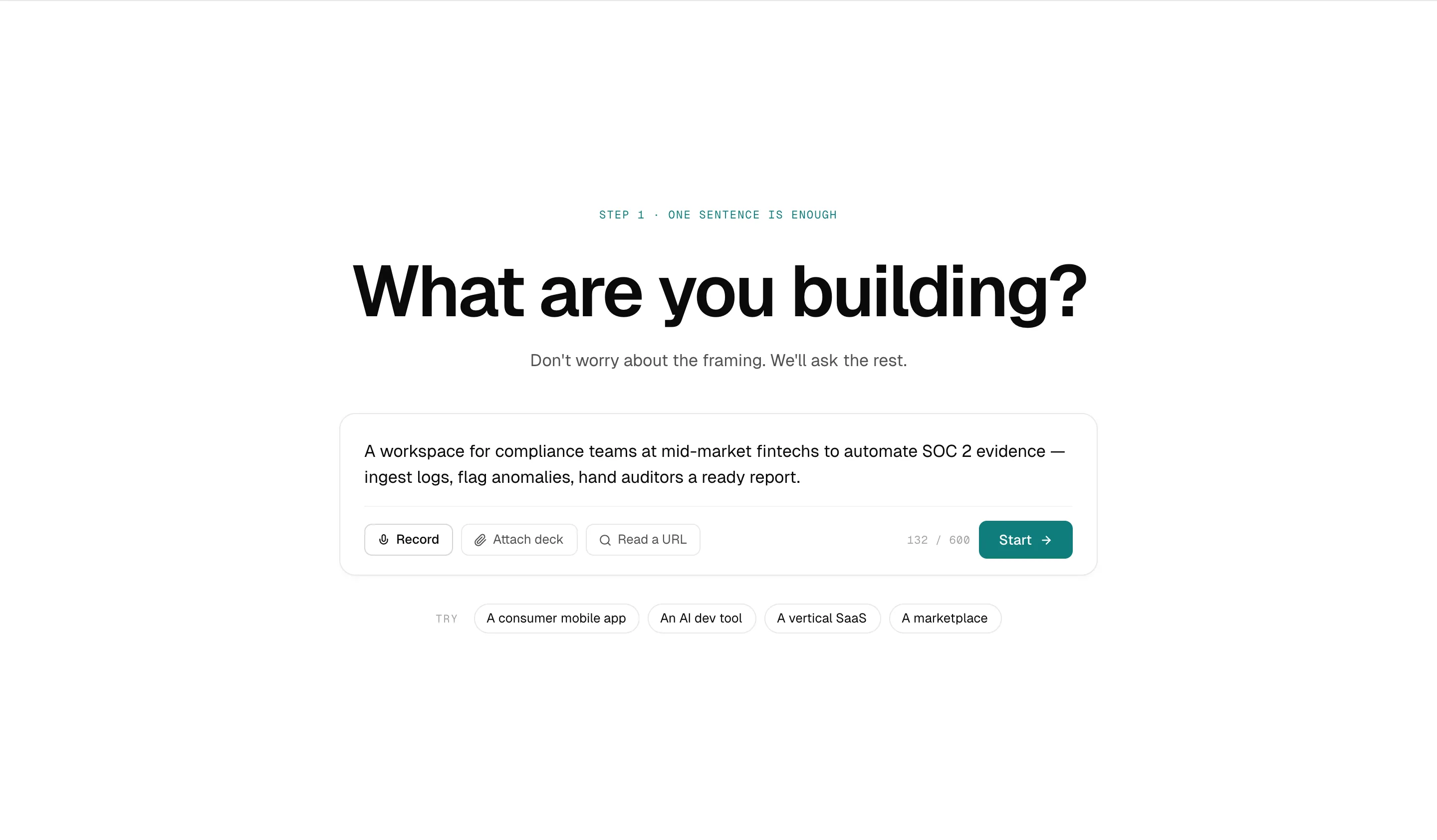
- · One-sentence pitch
- · ICP guess
- · Pricing hypothesis
- · 10× claim
- · Named falsifier
- · Structured brief
- · Hypothesis tree
- · Coverage map
- 01Brief is parsed into a hypothesis tree (one root claim, three to five child claims, leaf evidence requirements).
- 02Each child claim is tagged with a kill criterion and a required evidence tier.
- 03Coverage map identifies which sources, datasets, and competitor surfaces each leaf needs.
Claude Sonnet 4.6 (brief parser) · GPT-5 (hypothesis tree validator)
Market sizing
Bottom-up TAM built from unit economics, SAM from ICP density, SOM from year-one capture; top-down Gartner numbers do not qualify.
- · ICP definition
- · Pricing hypothesis
- · Geography
- · Comparable wedges
- · TAM / SAM / SOM table
- · Sizing memo
- · Growth rate range
- · WTP signals
- 01Bottom-up TAM from primary databases (SEC EDGAR, FRED, BLS, Eurostat, ONS, Census).
- 02SAM derived from ICP density × ACV band, cross-checked against three comparable wedges.
- 03SOM modeled across three GTM scenarios (founder-led, PLG, channel) with named penetration ceilings.
- 04Growth rate triangulated from at least two independent sources; conflicts flagged, not averaged.
Claude Sonnet 4.6 (sizing reasoning) · Perplexity Sonar Pro (source corroboration) · GPT-5 (numerical sanity check)
Competitive map
Direct competitors, indirect substitutes, and the do-nothing baseline scored on the same six axes, with the reach-for substitute named.
- · Category definition
- · ICP workflows
- · Wedge claim
- · Substitute hypotheses
- · Competitor scorecard
- · Substitute map
- · Moat thesis
- · Threat ranking
- 01Direct competitor sweep across Crunchbase, PitchBook, G2, Capterra, Product Hunt, and recent funding announcements.
- 02Indirect substitute mapping: open source, in-house build, spreadsheet, services firm, do-nothing.
- 03Each player scored on feature parity, distribution reach, capital position, hiring velocity, integration surface, and switching cost.
- 04Moat thesis tested against the strongest competitor's most recent 90 days of shipping cadence.
Claude Opus 4.7 (competitive synthesis) · GPT-5 (capital and hiring signal extraction) · Gemini 2.5 Pro (long-context competitor doc ingestion)
10× claim test
Your 10× claim is decomposed into measurable sub-claims and run against the falsifier you named; untestable claims do not survive.
- · 10× claim
- · Falsifier criterion
- · Benchmark targets
- · Comparable products
- · 10× audit
- · Benchmark grid
- · Falsifier check
- · Adversarial transcript
- 01Claim is decomposed into measurable sub-claims (latency, cost, accuracy, coverage, time-to-value).
- 02Each sub-claim is benchmarked against the named competitor and the do-nothing baseline.
- 03Falsifier criterion is run as an inverse test: if the criterion holds today, the claim is downgraded.
- 04Adversarial pass: a second model tries to break the claim from the strongest counter-argument.
Claude Opus 4.7 (claim decomposition) · GPT-5 (adversarial counter-argument) · o4-mini (numerical benchmark verification)
Synthesis & verdict
Multi-section research report drafted to a fixed template: verdict on the cover, kill criterion named, sections for market, competition, the 10× test, pricing, and (when the call is BUILD) a 12-week build plan and GTM motion analysis. Tier-graded citations inline. Two audience frames in one memo. Timestamped run record at ship.
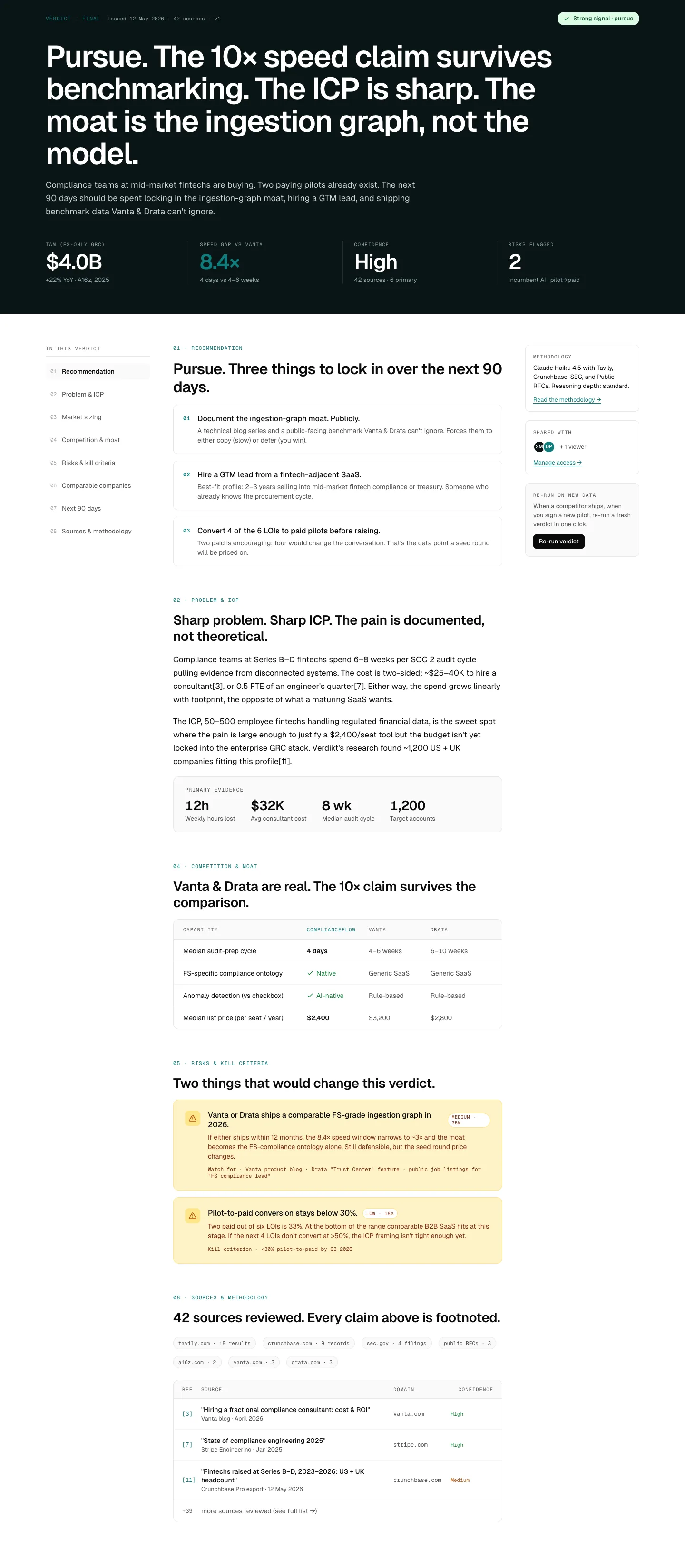
- · All prior stage outputs
- · Reasoning traces
- · Citation pack
- · Quality gate results
- · Multi-section report
- · Citation pack (~40 cited)
- · Founder / investor dual frame
- · Reasoning trace
- · Re-run hooks
- · Run record & timestamp
- 01Memo drafted to a fixed template; deviations from template require explicit override and are flagged in metadata.
- 02Recommendation is one of: BUILD, PIVOT, KILL (founder frame) or PURSUE, RECONSIDER, REJECT (investor frame). Both frames ship in the same memo. No fourth option.
- 03Kill criterion restated verbatim with the evidence threshold that would trigger it.
- 0414 quality gates run on the draft; any failure blocks ship and returns to the relevant stage.
- 05A run record is emitted alongside the memo: generation time, pipeline version, model lineup, gate results, and re-run hooks for the three weakest claims.
Claude Opus 4.7 (memo composition) · GPT-5 (gate verification) · Claude Haiku 4.5 (citation linting)
What ships is a memo, not a paragraph.
The deliverable is not a paragraph, it is a multi-section research report with the verdict on the cover and every claim cited inline. Same evidence, two lenses: the founder frame reads first, the investor frame ships beside it for cofounder alignment, advisor reviews, and partner meetings.
Should you ship it? Quit your job? Pivot the wedge? The report reads end-to-end as a builder's memo.
Each section ships with a reframe panel: same evidence, the partner-meeting lens. Standard pre-seed comp set, named kill criteria, IC-packet ready.
Seven models. Each one used where it is strongest.
One model is one opinion. The pipeline routes each task to the strongest model, then to a different lineage for adversarial review. Different training data, different failure modes.
Every citation is tier-marked.
A claim from the SEC and a claim from Reddit aren't the same claim. Numbers your deal hinges on come from Tier 1. Tier 2 is context. Tier 3 is reading the room.
We pull from 180 named sources below. A typical report cites about 40 of them, chosen for relevance to your idea and weighted by tier. Every cited URL is fetched and the claim grep-verified before ship.
SEC, USPTO, FRED, BLS, Eurostat, Gartner, IDC, Forrester, peer-reviewed. Where the deal numbers come from.
The Information, Bloomberg, FT, Reuters, Stratechery, MIT Tech Review, HBR. Context and corroboration.
G2, Hacker News, Reddit, Glassdoor. To read the room. Never as fact.
Fourteen checks. Any failure blocks ship.
Fourteen automated gates. A failure returns the draft to the relevant stage with the flagged claim. The memo you receive is the one that passed all fourteen.
Every verdict names what would change the call.
We name the specific evidence that would flip the call. The leading incumbent ships parity in 18 months. Cycle stretches past 14. ICP shrinks below 4,000. If it shows up, the verdict changes. (Illustrative example.) That's the difference between a useful memo and a confident paragraph.
You stake it. The pipeline can't test what you haven't.
Run as an inverse claim. If it holds today, the verdict downgrades.
Reproduced in the memo with the threshold that would trigger a re-run.
What Verdikt refuses to do.
A methodology is defined by what it rejects. Six things the pipeline won't do.
No Gartner number times an arbitrary penetration rate. Top-down-only TAM is flagged and the claim is downgraded.
No recommendation rests on one source. Without two independent Tier 1 inputs, the claim drops to NEEDS MORE EVIDENCE.
When two credible sources disagree, both are shown with the gap explained. Quiet averages make bad decisions.
No 'strong network effects' without a metric trending the right way. Otherwise the moat is marked speculative.
No 'it depends.' Four discrete calls with a named kill criterion. We will be wrong sometimes, never vague.
Your brief, trace, and memo never train any model. Zero retention on every LLM call.
Verdikt reports are advisory research, not legal, financial, investment, or business advice.